void foo(int i)
{
char *dest;
dest = malloc(A_SUFFICIENT_SIZE);
/* assume, for the sake of argument, that malloc()
can never return NULL... */
int x = i / 10 + 2; 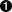 sprintf(dest, "%d", x);
}
sprintf(dest, "%d", x);
}
NewC
Permission is granted to copy, distribute and/or modify
this document under the terms of the GNU Free Documentation
License, Version 1.1; with no Invariant Sections, with no
Front‐Cover Texts, and with no Back‐Cover Texts. A copy of the
license is included in Appendix B, GNU Free Documentation License
.
CVS Id: $Id: c-changes.xml,v 1.7 2003/01/23 18:30:54 micah Exp $
This document provides a brief overview of the changes in
the C programming language as defined by the international
standard, ISO/IEC 9899:1999 (known as C99
), since
the previous release of that standard in 1990 (as ammended;
known as C90
).
This document is a WORK IN PROGRESS; it is missing major portions, and may have glaring errors. I’m still working on it.
This document was generated from DocBook XML using Apache’s Xalan XSLT processor. The source document is here, and the XSLT transform source is here. Note that these will probably not work for you off the bat; they use the SYSTEM identifiers for public DTDs, because I currently write this from my laptop, and my XSLT processor doesn’t handle OASIS catalogs. You will also need to obtain the DocBook version of the GNU Free Documentation License, and the acronym mapping file.
At some point, I may make TeX and PDF versions of this document available.
Top | Up | Prev | Next | Up and Next
In 1999, a joint committee of the ISO and IEC international standards organizations finalized a new edition of ISO/IEC 9899, the standard that defines the C programming language.
At the time of this writing, three years after the finalization of the standard’s second edition, only one conforming implementation is known to exist: Comeau Computing’s compiler combined with DinkumWare’s library. Actually, this combination is also currently the only 100% conformant C++ implementation.
However, more new implementations which conform to the new edition, including future versions of GCC and glibc, are expected to be produced in the very near future. In fact, most C implementations currently on the market already support many (but not all) of the new features and semantics in the 1999 standard. This being the case, it would seem wise for current developers to bring their knowledge of the language up‐to‐date in preparation for these new implementations, in order to be able to take advantage of the new features as soon as C99‐conformant1 implementations are more common‐place, and to ensure that current code is forward‐compatible with some of the changes that represent incompatibilities with the previous edition of the standard.
That’s where this document comes in. Its purpose is to inform the reader of the most significant changes to the languages since the first edition of the language specification (as ammended). While it covers a very large number of differences between the two specifications, it is not exhaustive; there are a number of more subtle changes which are not covered here—for example, the changes in the rules for type determination of numeric literals, or the various rules from C90 which have been made more precise through subtle changes in wording.
The changes discussed in this document have been grouped into three categories:
New features which are similar to features which exist in the C++ language
New features which are similar to common extensions by compiler vendors
New features which are “truly new,” bearing litle resemblance to C++ or common extensions, to the best of this author’s knowledge.
Of course, this grouping is imprecise, as there are features which could fall into more than one category: for example, may of the new features which exist in C++ are also common vendor extensions. There are also features in the third category which are probably extensions in some implementations.
It is hoped that this subdivision will make for as easy a learning curve as possible, introducing those features with which the reader is most likely to be familiar first, and saving the more foreign concepts until later.
Top | Up | Prev | Next | Up and Next
This section contains features new to C99 which are very similar to features which may be found in C++. While one or two of these features are identical to their C++ counterparts, most of them are subtly but significantly different, so I’ve done my best not to let you confuse them.
Top | Up | Prev | Next | Up and Next
It used to be that the shortest possible C program was the very short construct:
main(){}assuming, of course, that the value returned by this problem is not used, since that value would be unspecified.
This construct was legal because, when no return type was specified for a function, an implementation would assume a return type of int. It is no longer; implicit function return types have been removed. So the shortest possible C program is now:
int main(){}However, the good news is that this line is more defined
than its C90 counterpart; as in C++, rolling off
the end of main() now has the same effect
as returning 0. Of course, the line
now has the problem that empty parameter
lists are deprecated… so for forward‐compatibility, we
should go with:
int main(void){}Top | Up | Prev | Next | Up and Next
Implicit function declarations have been removed from the language. All functions must have a declaration visible from the current scope before they may be called. This should be helpful in avoiding accidental bugs arising from forgetting an important header file, such as in the following code snippet:
int main(int argc, char *argv[])
{
long result;
if (argc > 1)
{
result = strtol(argv[1],NULL,0);
/* Uh oh! stdlib.h wasn’t included, so the compiler will
expect strtol() to return an int rather than a long!
Undefined behavior! */
}
return 0;
}
Top | Up | Prev | Next | Up and Next
C++’s infamous single‐line comments have been
reincorporated into C1.
In case you are such a Standard
C
purist that you have no idea what I’m talking
about…
int main(void)
{
// They
// look
// like
// this
return 0;
}
Top | Up | Prev | Next | Up and Next
Another C++‐ism, the ability to mix declarations with code statements, has now become a C‐ism, too. Consider:
void foo(int i)
{
char *dest;
dest = malloc(A_SUFFICIENT_SIZE);
/* assume, for the sake of argument, that malloc()
can never return NULL... */
int x = i / 10 + 2;
sprintf(dest, "%d", x);
}
Formerly, would have been
illegal; in C90, all declarations must occur before any
statements within the same block. In C99, however, the code is
completely legal; declarations and code may be freely intermixed
within the block.
This does not mean that a declaration is legal in any place that a statement is. In C++, a full declaration can be a statement; in C99, however, declarations and statements are completely independant syntactically; they may simply be intermixed freely within a block.
This may seem like a pointless distinction; but consider the following code, which may be legal in C++, but not in C99.
void handle_event(Event_t *evt)
{
switch (evt->type)
{
case EVT_WINDOW:
handle_window_event(evt);
break;
case EVT_MENU:
int menu_no, item_no;
menu_no = (evt‐>menu_info & 0xff00) >> 16;
item_no = (evt‐>menu_info & 0xff);
handle_menu_event(menu_no, item_no);
break;
default:
handle_misc_event(evt);
}
}
The declaration at is still
illegal in C99: labeled statements are just that—statements! And
since in C99 a declaration is still not a statement, you just
can’t stick a label in front of it.
One way around this problem is to immediately follow the label with a null statement—a single, solitary semicolon, like so:
case EVT_MENU: ; int menu_no, item_no;
And, one can still follow the label with a block statement:
case EVT_MENU:
{
int menu_no, item_no;
…
}
This, of course, is still legal in C90 as well.
Top | Up | Prev | Next | Up and Next
The new edition of the C programming language has borrowed another C++‐ism: a declaration may be used for the first clause of a for statement.
#include <stdio.h>
int main(int argc, char *argv[])
{
for(int i=0; i!=argc; ++i)
{
printf("Argument %d: %s\n", i, argv[i]);
}
return 0;
}
As expected, i’s scope and lifetime will extend for the duration of the for statement.
However, unlike C++, C99 still doesn’t allow declarations in the condition of a selection statement (such as if), or other iterative statements (such as while). For example, the following code, while legal in C++, is still illegal in C99:
char *my_strcpy(char *dest, const char *src)
{
char *retval=dest;
while (char c=*src++) // Illegal!
*dest++=c;
return retval;
}
Top | Up | Prev | Next | Up and Next
C99 now has a boolean built‐in type, _Bool, which can hold either 0 or 1. Now, you might be wondering why I stuck that in here, since C++ and common vendor extensions call their built‐in type bool. But _Bool was designed to be similar to C++’s built‐in boolean type; all you have to do is include the <stdbool.h> library header, which defines macros as follows:
#define bool _Bool #define true 1 #define false 0
All true values (meaning C’s concept of
true
) converted to type _Bool become
the value 1; false values become the value
0.
All integer values of a rank lower than int (_Bool, for instance) are converted to type int for use in expressions (if the value can be represented as an int; otherwise it will be converted to unsigned int). So, for instance:
#include <stdbool.h>
int main(void)
{
bool b;
b = 5;
++b; 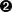 b += 22;
b += 22;  --b;
--b;  --b;
--b;  return 0;
}
return 0;
}
After , b has
the value 1. But even after , b’s value is
1, since its value will first be converted to
int before it is incremented, after which it will
be converted back to 1 for representation as
a _Bool. Not even will
affect the final value of b. Since
b’s value remains the same, it is only after
that b’s value is
finally affected, since that expression is equivalent to
b = b − 1, which in turn
is equivalent to
b = 1 − 1; so
b gets the value
0. However, after the exact same expression
at , the value is returned to
1 (true), since the
expression is now equivalent to
b = 0 − 1, resulting in
the value −1, which then becomes
1 when converted to
_Bool.
Top | Up | Prev | Next | Up and Next
enum declarations now allow you to place an extra comma after the last enumerator in the list; e.g.:
enum
{
red,
orange,
yellow,
green,
blue,
indigo,
violet,
}
Presumably, this is to make the coder’s job easier, should he wish to add ultraviolet to the list.
Top | Up | Prev | Next | Up and Next
Another C++ feature which is also a common vendor
extension, is the inline
function specifier, which is used to declare and define
inline functions. The only difference
between an inline function and an ordinary function is that
making a function inline suggests to the implementation that
calls to that function be as fast as possible.
Obviously, this is a rather vague definition—in fact, an
implementation is welcome to handle it by not doing anything
special at all. However, the intention is that, wherever
practical, an implementation can produce object code in‐place
that accomplishes the same thing as the inline function, thus
avoiding the overhead of making room on the stack, calling the
function, and handling the return values.
However, it’s important to understand that inline functions in C99 are different in some subtle‐but‐significant ways from how they are implemented both in C++ and in common vendor extensions.
Top | Up | Prev | Next | Up and Next
While any function with internal linkage (that is, a function declared with the static specifier) can be made an inline function simply by adding the inline specifer to a declaration of that function, there are some special restrictions on inline functions with external linkage: the function body may not define an object with static storage duration, and it must not refer to an identifier with internal linkage. Also, if any declarations of an external function include the inline specifier, a definition of that function must exist in the same translation unit.
Top | Up | Prev | Next | Up and Next
If all the declarations at file‐scope for an externally‐linked inline function contain the inline specifier but not extern, the function’s definition within that translation unit is provided for use within that translation unit only (inline definition): no external definition is supplied.
However, it is unspecified whether a call to that function uses the inline definition, or an external one—therefore, an external definition must be supplied in another translation unit, in addition to the inline definition.
Top | Up | Prev | Next | Up and Next
C++ requires that if an external function is declared inline in one translation unit, it must be declared to be inline in all other units in which it appears. This means that the following example, while legal in C99, would be illegal in C++, and invoke undefined behavior at link‐time:
uninlinedinline function
// foofun.h
extern void foofun(void);
extern void barfun(void);
// foofun.c
#include <stdio.h>
#include "foofun.h"
inline void foofun(void)
{
puts("Hello, there!");
}
void barfun(void)
{
foofun(); // This call could be inlined.
}
// main.c
#include "foofun.h"
int main(void)
{
foofun(); // This call uses the external definition.
barfun();
return 0;
}
This would invoke undefined behavior in C++ because foofun()’s declaration in main.c did not specify inline. Note that the external definition of foofun() was provided by foofun.c, because of the inclusion of foofun.h which declared foofun() at file‐scope using the extern specifier. If extern had been omitted, then foofun.c would have produced only an inline definition and not an external one, leading to undefined behavior at link time.
C++ also specifies that every definition of an inline function be exactly the same. This requirement is not made in C99, so here is another example which is legal in C99 but not in C++:
// foofun.h
inline void foofun(void);
extern void foofun(void);
// foofun.c
#include <stdio.h>
#include "foofun.h"
inline void foofun(void)
{
puts("foofun() was called inline!");
}
extern void barfun(void)
{
foofun(); // This could use either the inline definition
// above, or the external definition from main.c.
}
// main.c
#include <stdio.h>
#include "foofun.h"
// This conflicting definition would be illegal in C++
extern inline void foofun(void)
{
puts("foofun() was called inline or via its external definition!");
}
int main(void)
{
foofun(); // The definition above will be used, whether or
// not it is inlined.
barfun(); // Either/or (indirectly).
return 0;
}
One other restriction in C++ which is not made in C99, is that inline function declarations are forbidden at block scope:
#include <stdio.h>
int main(void)
{
inline void foobar(void); // Illegal in C++
foobar();
return 0;
}
extern inline void foobar(void)
{
puts("foobar() called.");
}
Top | Up | Prev | Next | Up and Next
It’s worth noting that while many implementations of C
prior to C99 provide inlined functions as an extension, there
are often important distinctions to how they are
implemented. For example, in GCC, an
external definition is always provided for non‐static inline functions
unless extern is specified: which is
essentially the opposite of the C99 semantics. At the time of
this writing, GCC uses these semantics (and acknowledges their
incorrectness) even when the ‐std=c99
command‐line option is given. Until such disparities are
resolved, it wouldn’t be a bad idea to make up your own
keywords,
#defineing them as appropriate to
obtain the desired semantics.
For example, you could make the following definitions in C99:
#define inline_with_external_def extern inline #define inline_def inline #define inline_with_internal_def static inline
Whereas in GCC you could define them as:
#define inline_with_external_def inline #define inline_def extern inline #define inline_with_internal_def static inline
And in straight‐up ISO Standard C without extensions:
#define inline_with_external_def #define inline_def #define inline_with_internal_def static
Top | Up | Prev | Next | Up and Next
Ever since the first official standard was released, C has
supported limited character sets and limited keyboards through
trigraphs (see §2.9.1, Trigraphs
). The support has
been enhanced with digraphs and a small macro library. These new
facilities are more intelligently implemented, and won’t tend to
get in the programmers way, as the trigraphs unfortunately do (to
the point that most implementations turn them off by default,
unless invoked in ISO‐conformance
mode.)
Top | Up | Prev | Next | Up and Next
Lets begin with a review of trigraphs. Trigraphs are sequences which begin with two question‐marks followed by one another character. These sequences are then replaced early in the preprocessing with a single character. Most people don’t use them much, and in fact, most compilers don’t translate them unless you invoke them in strict standard‐conformance mode, so I won’t be surprised if you don’t remember them. Here they are for reference:
| ??= | # | ??) | ] | ??! | | |
| ??( | [ | ??' | ^ | ??> | } |
| ??/ | \ | ??< | { | ??- | ~ |
The problem with trigraphs is that they can lead to surprising results when you’re not careful, because they are always replaced with their equivalent, no matter where they occur. For example, the following inoccuous line of code:
printf("You did what??!??\n");
contains the trigraph ??! and so is really equivalent to:
printf("You did what|??\n");
which probably wasn’t the intention. In order to get what the desired result, you would need to do something like:
printf("You did what?\?!??\n");
Top | Up | Prev | Next | Up and Next
Both C++ and C99 have now added digraphs, which have the advantages that: 1. They are one character shorter to type than the equivalent trigraphs, and 2. They do not interfere with string literals the way that trigraphs do.
There are six digraphs:
| <: | :> | <% | %> | %: | %:%: |
| [ | ] | { | } | # | ## |
The equivalent token is displayed under each digraph in the table above.
A major difference between digraphs and trigraphs is that while trigraphs are expanded to a single character equivalent early on during preprocessing, digraphs are never expanded at all: they are seperate tokens in their own right—they just happen to have precisely the same meanings as their counterparts. So the following code:
%:include <stdio.h>
int main(void)
<%
puts("This program includes the digraphs '%:', '<%' and '%>'.");
return 0;
%>
will produce the output:
This program includes the digraphs '%:', '<%' and '%>'.
While this code:
??=include <stdio.h>
int main(void)
??<
puts("This program includes the trigraphs '??=', '??<' and '??>'.");
return 0;
??>
will produce:
This program includes the trigraphs '#', '{' and '}'.
Top | Up | Prev | Next | Up and Next
C++ also defines several other alternative tokens for some key logical and bitwise operators, some of which are also useful for avoiding characters which may not be available on some keyboards. These tokens are given below on the left, with the primary tokens they are equivalent to on the right.
| and | && |
| and_eq | &= |
| bitand | & |
| bitor | | |
| compl | ~ |
| not | ! |
| not_eq | != |
| or | || |
| or_eq | |= |
| xor | ^ |
| xor_eq | ^= |
C99 has added something similar; except that instead of offering them as alternative tokens, which could run the risk of breaking code which uses one of them as an identifier, they are offered as macro definitions in the header file iso646.h, which is named after a series of 7‐bit character encodings which lack some of the characters #, $, @, \, ], ^, `, {, |, }, and ~, depending on the encoding.
#include <iso646.h>
#include <stdio.h>
#include <string.h>
int main(int argc, char **argv)
<%
if (argc == 2 and (not strcmp(argv[1], "arg"))
or (not strcmp(argv[1], "argument")))
<%
printf("You passed \"arg\" as an arg!??/n"); // Note: ??/ = \
%>
return 0;
%>
Top | Up | Prev | Next | Up and Next
This section describes features which are likely to be familiar to C programmers, as they correspond to features which are frequently found in existing C implementations as extensions to the official language. Of course, the problem with depending on such extensions is that, since they are not in the standard, they cannot generally be counted on for portability. But when extension become de facto standard, it often indicates a deficiency in the language, so it is natural that they be included in the next round of standardization.
Top | Up | Prev | Next | Up and Next
The need for an integer type capable of holding 64 bits has been growing, but until now standard C’s largest type, the long int, has only guaranteed 32 bits. Because of the need for the larger type, many vendors have included an additional integer type, the long long int and its brother, the unsigned long long int. These types are now part of the standard language.
Of course, there still remains the question of how to use
the fprintf() family of functions to print
the value of a long long or unsigned long
long, and how to determine the minimum and maximum values
for them. For the former, the ll length
modifier has been added, meaning that the following
d, i,
o, u,
x, or X conversion
specifier applies to a long long or unsigned
long long, or that the following n
conversion specifier applies to a pointer to long
long. See also §4.3.1.2, Conversion Specifiers
Note that those vendors which provided long
longs of their own have not always agreed on what length
modifier to use for them. The L modifier was
already in use with the floating point specifiers to indicate
long double, so many vendors thought, why not use
it with the integer specifiers to indicate long long
int? BSD 4.4 decided to use q (for
quad
). Neither of these made it into C99, so
you’ll be a good deal safer if you stick to
ll.
As to determining the limits of these new types, C99 has added a few new macros to the limits.h header file: LLONG_MIN, guaranteed to be at most −(263 − 1); LLONG_MAX, guaranteed to be at least 263 − 1; and ULLONG_MAX, at least 264 − 1.
To specify a long long or unsigned long long literal, you can append LL or ULL to the end of the number, respectively; e.g., 80972ULL or -346002LL. The lowercase equivalents ll and ull may also be used.1
You forgot to mention strtoll() and strtoul().
Top | Up | Prev | Next | Up and Next
Up until now, array definitions have required the use of a
integer constant expression, resolvable at compile‐time, in
specifying the number of elements in the array. C99 now allows
you to define the size of dynamically allocated arrays using
integer expressions to be evaluated at runtime. Such arrays are
called Variable Length Arrays
, or
VLAs.
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
size_t vla_size, elem;
int result = 0;
fputs("Please enter the number\n"
"of elements to allocate for the VLA: ", stdout);
fflush(stdout);
// Read in a number.
scanf("%zu", &vla_size); // (I never use scanf() in _real_ programs)
// See §4.3.1.1, Length Modifiers
// about the 'z' conversion specifier.
int my_vla[ vla_size ];
// Fill the VLA with pseudo-random data
// (we don't bother to seed, so we'll get the same
// values for each run).
for (size_t i=0; i!=vla_size; ++i)
my_vla[i] = rand();
for (;;) // ever
{
fputs("Display which element of the VLA? ", stdout);
result = scanf("%zu", &elem);
if (result == EOF)
break;
if (elem < vla_size)
printf("%zu: %d\n\n", elem, my_vla[elem]);
else
printf("There is no element %zu!\n\n", elem);
}
return 0;
}
One advantage offered by the VLA over the standard C malloc() memory allocation function is that objects allocated as a VLA will be automatically deallocated when the block they were created in is executed, whereas malloc()ed objects must be explicitly free()d. Another advantage is that the VLA is more strongly typed than the void * returned by malloc(). Of course, there are many cases where you don’t want the memory you allocate to disappear upon exit of a block. And a definite disadvantage to using a VLA is that, unlike with malloc(), you cannot resize an object after it has been allocated (i.e., with realloc()).
When trying to decide whether an array is a
VLA or not, remember that, unlike C++, a
variable whose type is a const‐qualified
integer is not a constant integer
expression
. Thus, in the code below:
int main(void)
{
const int array_size = 10;
int array[array_size];
return 0;
}
array is a VLA; even though in C++, it would be a perfectly normal array.
Top | Up | Prev | Next | Up and Next
New syntax has been added for declaring VLAs within function prototypes.
void myfun(size_t ary_size, int ary[ ary_size ]);
Or, for prototypes without identifiers, you may also use * in place of the identifier to indicate a VLA:
void myfun(size_t, int [*]);
This does not work in GCC.
Of course, since array types become pointer types in function prototypes, neither of these are any different from
void myfun(size_t, int []);
or
void myfun(size_t, int *);
However, it becomes somewhat more useful is when dealing with multidimensional VLAs:
void myfun2(size_t ary_size, int ary[ary_size][ary_size]);
In this case, ary is a pointer to a VLA whose size is ary_size.
Top | Up | Prev | Next | Up and Next
Top | Up | Prev | Next | Up and Next
As with any array type, you can use a VLA as the operand to sizeof. However, since the size of a VLA is generally not known until runtime, this means that not all sizeof expressions are compile‐time constants anymore, either.
The rule for whether or not a sizeof expression is a compile‐time constant or not is this: if sizeof’s operand is a VLA, or any object type whose declaration contains a VLA declaration nested within the full declaration (e.g., pointer to VLA, or array of VLAs, or array of pointers to VLAs… such types—including VLAs—are called variably modified object types), then its value is determined at runtime; otherwise, it will be a compile‐time constant.
It’s also very important to realize that, while the operand to the compile‐time version of sizeof is never evaluated, an operand of variably modified type is evaluated. Consider:
#include <stdio.h>
int main(void)
{
int foo = 10;
int (*ary)[10]; // Pointer to array of 10 ints
int (*vla)[foo]; // Pointer to VLA of foo (10) ints
printf("The size of (*ary)[0] is %zu.\n", sizeof ((*ary)[0]) );
printf("The size of (*vla)[0] is %zu.\n",
sizeof ((*vla)[0]) ); // No no no no...
return 0;
}
The first sizeof expression is fine, since the operand to sizeof is not normally evaluated. However, the operand to the second sizeof is evaluated, and results in the value of the first element of the VLA pointed at by vla. However, since we never actually allocated any memory for vla, dereferencing it is a Very Bad Thing™.…
GCC does not conform in this regard.
Top | Up | Prev | Next | Up and Next
Some C implementations provide a facility called
alloca(), which allocates space similarly
to malloc(), but the objects so allocated
are deallocated upon exit from the function in which
alloca() was called. This facility was
not to be found in any standard, however, so its use was not
portable. VLAs provide the same convenience
as alloca(), plus the advantage of
stronger typing, and size determination via
sizeof (see §3.2.3, VLAs and the
sizeof Operator
). And, of course,
VLAs will be substantially more portable
once implementations of the C99 language have become more
widespread.
Top | Up | Prev | Next | Up and Next
The previous C standard required the initializer‐list for
initializing aggregates (structs and arrays) to contain only
constant expressions for the initializers, which must be
specified in the same order as they are specified in the struct,
or as they are stored in the array. Only the first member of a
union could be initialized: i.e., if a union contains an int and
a double member, respectively, you could not initialize the
union to hold a double value, though you could
assign it the double value after
definition. Any initializers left unspecified would receive
their default
initialization (zero for arithmetic
types, null for pointers; aggregates are initialized similarly
for each element or field); but you could not, for example,
specify initialization for a couple fields in the middle while
leaving fields on the ends to be default‐initialized.
This has all changed with the new standard; not only can you now use non‐constant initializers for aggregates, but you can specify them in any order you choose. This is accomplished by providing optional designators for the initializers, followed by the equal sign (=) before the initializers. Designators for struct fields take the form .field‐name; array element designators take the form [element‐number]. Note that while initializers no longer need be constant expressions, the element number for array element designators must be.
struct my_struct_t
{
int id;
double x, y;
double misc;
}
my_struct = { .x = 1.0, .y = 5.2 };
int my_array[10] = { [4] = 1, [5] = 1, [1] = 3, };
As you can see from the last line of the example above, a final spurious comma is now permissible at the end of the initializer‐list (as in C++).
You can also use designators for recursive initialization (i.e., aggregates‐within‐aggregates), simply by stacking initializers:
struct my_other_struct_t
{
double a;
int b;
char *strs[2];
}
another_struct = { .a = 3.14159, .strs[0] = "another",
.strs[1] = "example", .b = 4 };
The initialization of the strs field could also have been written as:
another_struct = { …,
.strs = { [0] = "another",
[1] = "example" }, … }
Designated initializers can be especially useful when using an array as a lookup‐table using, e.g., character values or enumeration constants:
enum { red, green, blue };
typedef unsigned char Color_spec[3];
Color_spec my_color = { [red] = 0xff, [green] = 0xee, [blue] = 0x0 };
Since we’re in §3, Features Similar to Common Vendor Extensions
, it
should be clear to you that this is also frequently found as an
extension in C implementations prior to the new standard;
however, the syntax frequently varies from that of the new
standard. For example, GCC has offered a
similar mechanism (for structs only) for quite some time;
however, the syntax for
struct my_struct_t my_struct = { .x = 5.0 };
was
struct my_struct_t my_struct = { x: 5.0 };
In versions since 2.5, GCC has considered this syntax obsolete in deference to the anticipated syntax from C99. However, if you look at (for example) the source code for the Linux kernel, you’ll frequently encounter the older syntax. Newer code should use the C99 syntax whenever possible, in case GCC decides to drop the old syntax in the future.
Top | Up | Prev | Next | Up and Next
Along with VLAs, one of my very
favorite new features of the C99 language is the addition of
compound literals. These are temporary, unnamed objects which
can be expressed very concisely, and whose lifetime lasts until
the end of the block in which it was created. They are
lvalues
, and so may be written to as well as read
from.
Compound literals can save a lot of typing when you want to express a complex (struct or array) value for very brief use—perhaps just for use in one line (a function call, for example)—and don’t need to refer to it again.
Consider this code snippet in C90, which creates an object of type struct tm, to be converted to a time_t:
#include <time.h>
…
struct tm t = {0}; // Zero the fields.
time_t u;
t.tm_year = 1977 - 1900; // 1977
t.tm_mon = 12 - 1; // December
t.tm_mday = 10; // 10th
u = mktime(&t); // u now holds the seconds since the epoch
// for 10 Dec 1977.
…
Of course, you could also specify those values in the
initializer for t; but without the
designators (§3.3, Designated Initializers
) it’d
make for somewhat less‐than‐readable code.
In C99, you can reduce the entire snippet above (excluding the #include directive) to:
time_t u = mktime( &(struct tm)
{
.tm_year = 1977 - 1900, // 1977
.tm_mon = 12 - 1, // December
.tm_mday = 10 // 10th
} );
The code above creates a temporary struct tm object, instead of a variable complete with identifier. Note that mktime() writes back to its argument—this is perfectly fine, since compound literals are lvalues (and since our example wasn’t const‐qualified, it’s a modifiable lvalue).
As you can see, compound literals look pretty much like a brace‐enclosed list of initializers, cast to the appropriate type. To be a little more accurate, it consists of a type specification enclosed within parentheses, followed by a brace‐enclosed initializer‐list.
Let’s try another one. You can use array literals to make a pointer point at a temporary object that will last as long as the pointer does:
int *p2i = &(int []){ 5, 3, 7, 9, 9 };
Handy, huh?
It’s worth noting that the difference for scalars between a cast such as (int)1 and a compound literal such as (int){ 1 }, is that the latter is an lvalue, while the former is an rvalue.
GCC does not yet fully support the ISO C99 semantics—in particular, the values produced by compound literals are rvalues, not lvalues (and therefore not modifiable).
Top | Up | Prev | Next | Up and Next
Since time immortal, the C preprocessor has had a couple of special macros for locating the point of their evaluation within the source code. These macros are __FILE__, which is expanded to a string literal containing the name of the current source file, and __LINE__, which is expanded to the current line number (as an integer constant) within that file. While these are frequently very useful in debugging, it has frequently been wished that another, similar macro be provided which resolved to the name of the current function. So many vendors have offered such a macro as an extension, usually calling it __FUNC__.
Well, C99 has opted not to provide such a macro. However, it has provided something more or less equivalent: instead of a macro, C99 has decreed that C implementations behave as if the identifier __func__ were defined right at the beginning of each function definition:
static const char __func__[] = "function‐name";
Since __func__ is not a macro that
expands to a string literal, you cannot take advantage of the
preprocessor’s string literal concatenation to build a single
string literal, as you can with __FILE__, or
__LINE__ after stringization
(example):
#define STR(x) #x
#define REPORT_LOCATION fputs("I am at line " STR(__LINE__) \
" of file " __FILE__ ".\n", strerr)
Top | Up | Prev | Next | Up and Next
One addition to the C standard which is long overdue (in my opinion) is the snprintf() function. It works much like sprintf() (no n), except that it takes an additional size_t argument:
int snprintf(char *buffer, size_t bufsiz, const char *format, ...);
(Actually, the prototype above is not quite accurate: the
buffer and format
parameters are additionally qualified by the restrict qualifier. See §4.7, The restrict Type
Qualifier
for a description of the restrict keyword, and Appendix A,
for the actual prototype of
snprintf().)Restricted
Functions
The sprintf() function, which has
been around since the early days, allows you to take advantage
of the same conversion specifications available for use in,
e.g., printf(), except that the resulting
text is placed in a string buffer, whose location is passed to
sprintf(). The chief problem with
sprintf(), though, has been that there is
no way to tell it how much space is available in the buffer,
requiring the user to painstakingly evaluate each component to
determine how much space will be required to convert it into a
string before attempting to use
sprintf(). Naturally, lazy programmers
frequently skipped this step, opting instead to cross
their fingers
and hope that the buffer was large enough
for their needs, leading to potential buffer overflows and stack
smashing.
With snprintf(), though, the new parameter allows the programmer to specify the size of the buffer being passed in. snprintf() will only fill it with that many characters minus one, leaving the remaining char for the null termination byte.
snprintf() returns the number of characters that would have been written to the buffer had it been sufficiently large, not counting the termination byte. snprintf() also allows you to specify a buffer size of 0, in which case the buffer pointer can be NULL; this is useful for determining how much space should be allocated for the buffer before using it. If an encoding error occurs (i.e., the format wasn’t written correctly), it is indicated by returning a negative number.
C99 also provides vsnprintf(), which is to snprintf() as vsprintf() (no n) to sprintf(). Instead of taking a variable number of parameters at the end, it takes an object of type va_list, so that a wrapper function taking variable arguments can pass the va_list it obtained from an invocation of va_start() on to vsnprintf(). It’s prototype is similar to:
int vsnprintf(char *buffer, size_t bufsiz, const char *format, va_list args);
As with snprintf(), the actual
prototype may be found in Appendix A,
.Restricted
Functions
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
int main(int argc, char *argv[])
{
int exit_code;
if (argc < 3)
{
fputs("I need 3 elements in argv[].\n", stderr);
exit_code = EXIT_FAILURE;
}
else
{
const char format[] = "There are %d elements in the argv[] array"
"(not counting the final NULL argument).\n"
"The first three are '%s', '%s' and '%s'.\n";
int bufsz;
// Find out how much space we need for our buffer...
bufsz = snprintf(NULL, 0, format, argc, argv[0], argv[1],
argv[2]);
// If we got a negative number, we wrote the format wrong...
assert(bufsz >= 0);
// Gotta love VLAs and interspersed declarations...
// (§3.2, Variable Length Arrays
and
// §2.4, Intermixed Declarations and Code
)
char buffer[bufsz];
snprintf(buffer, bufsz, format, argc, argv[0], argv[1],
argv[2]);
exit_code = EXIT_SUCCESS;
}
return exit_code;
}
Top | Up | Prev | Next | Up and Next
For the most part, the features described in this section
are unique; found neither in C++ nor among the common vendor
extensions—although certain sections, such as §4.3, New Conversion Specifiers
, do contain some features which are
also found as common extensions.
Despite not being needed desperately enough to become frequently‐found extensions in existing implementatioins, almost all of them constitute significant improvements to the C language.
Top | Up | Prev | Next | Up and Next
Since the first C standard, return statements with expressions have not been allowed within functions whose return type is void. In C99, there is now an additional restriction for return statements, which is the counterpart to the first: a return statement without an expression may only appear in a function whose return type is void.
In the days before standardized C, before the void type, it was very common to leave off the type specification of a function (causing its return type to default to int) and not return any values. For example:
applnod(n) /* Non-prototype function declarations */
struct node *n; /* deprecated. Implicit type specifiers removed */
{ /* (§2.1, Explicit Function Return Type
). */
if (n == NULL)
return; /* Empty return statement. No longer legal
within non-void-returning functions. */
if (last != NULL)
last->next = n;
if (head == NULL)
head = n;
n->next = NULL;
last = n;
} /* Falling off the end is still well-defined, as
long as the return value isn't used. */
This was legal as long as the return value was not used by the caller. As you can see from the comments, the code above is no longer legal on more than one count; but the main point was to illustrate an old‐fashioned use of an empty return statement from within a function with a return type, which is no longer legal.
Also, it’s worth drawing attention to the first comment above: while not yet illegal, prototypeless function declarations have been deprecated—they should not be used in new code, as they may be removed from the language at some point in the future.
Top | Up | Prev | Next | Up and Next
C99 allows programmers to specify floating point constants in hexadecimal (base 16) with binary exponents (times 2 to some power).
These consist of a hexadecimal prefix (0x or 0X, followed by a string of upper‐ or lowercase hexadecimal digits, optionally separated by a point (.), followed by a binary exponent and an optional floating point suffix (one of F or f to specify float, or L or l to specify long double.
| Prefix | Whole Part | Point | Fraction | Exponent |
|---|---|---|---|---|
| 0x | ABC | . | DEF | p17 |
The string of hexadecimal digits, as with regular decimal digits in a decimal floating‐point constant, may consist of a string of digits without any point (AEFAEF), a string of digits followed by a point (AEFAEF.), a string of digits with an intervening point (AEF.AEF), or a point followed by a string of digits (.AEFAEF).
The binary exponent is specified by a P or p, followed by an optional sign and a string of decimal digits. The value specified by the hexadecimal string is multiplied by two to the power of the decimal number so specified. Note that, unlike in decimal floating‐point constants, the exponent portion of the literal is not optional.
0xAEF.AEFp9
The decimal value for the above is (10 × 162 + 14 × 161 + 15 × 160 + 10 × 16−1 + 14 × 16−2 + 15 × 16−3) × 29 = (2560 + 224 + 15 + 10/16 + 14/256 + 15/4096) × 29 = 2799.6833… × 29 = 1433437.875.
Top | Up | Prev | Next | Up and Next
A number of new conversion specifiers and modifiers have been added to the formatted input/output functions printf(), scanf() and family—and especially to the formatted time conversion facility strftime(). Also, some preexisting modifiers or specifiers have some new uses at their disposal. These are all described within this section.
Top | Up | Prev | Next | Up and Next
Unless otherwise specified, the modifiers and specifiers
described below are for use in both the
printf() and scanf()
families of formatted input/output functions. Descriptions of
conversion specifiers which require types are given for use in
printf() and family; for
scanf() and friends, assume the parameter
should be a pointer to
the type described,
unless a parameter type is explicitly given. Also, any length
modifiers described below which apply to the integer
conversion specifiers may also be applied to the
n conversion specifier, which will be
associated with a parameter of type pointer to
the signed integer type described.
Top | Up | Prev | Next | Up and Next
The ll modifier, used to indicate a
long long or unsigned long long
parameter, was described in §3.1, The long long Type
. There is also a new
hh modifier, which means that the
following d, i,
o, u,
x, or X conversion
specifier (hereinafter the integer conversion
specifiers
) applies to a parameter of type
signed or unsigned char (depending
on the exact specifier given). In the case of
printf() and friends, the type will
have been promoted according to the integer promotions, but
printf() will convert it back to
signed or unsigned char before
output.
The j modifier is used to indicate
that the following integer conversion specifier applies to
an intmax_t or uintmax_t, which
are types given in the stdint.h
standard library header; see §4.4, New Integer Type typedefs
for
a description of these types.
The z modifier is used to indicate that the following integer conversion specifier applies to a size_t, or to the corresponding signed integer type.
The t modifier is used with the integer conversion specifiers to indicate a ptrdiff_t, or the unsigned counterpart.
The l modifier already existed prior to C99, and was available for use with the integer specifiers to indicate long or unsigned long, and, for scanf(), with a floating point specifier to indicate a double. Its use is now allowed with floating point specifiers in printf() as well, though it has no effect.
It has a couple of new uses, though, as well: it may be used with a c specifier to indicate an argument of type wint_t; and with the s specifier to indicate an argument of type pointer‐to‐wchar_t.
Top | Up | Prev | Next | Up and Next
A new conversion specifier, a, is
used with a double argument. The value is converted to a
string representation of a hexadecimal floating‐point
literal (see §4.2, Hexadecimal Floating‐Point Literals
); e.g.,
0x89a.0fp+2. Lowercase alphabetic
characters are used for the x and
p, and for alphabetic hexadecimal
digits. The A specifier exists with the
same meaning as a, except that uppercase
alphabetic characters are used instead of lowercase. In
scanf() and related functions,
A and a have the same
meaning as all the other floating point specifiers.
A new conversion specifier, F, is provided with precisely the same functionality as f, except in one regard: for systems which are capable of expressing floating‐point values representing positive or negative infinities or not‐a‐number, all of the floating‐point conversion specifiers allow that to be indicated in the converted output: lowercase specifiers convert infinities to [‐]inf or [‐]infinity, and not‐a‐number representations to [‐]nan or [‐]nan(string), where string is a sequence of alphanumeric and the underscore (_) characters. The uppercase specifiers specify [‐]INF or [‐]INFINITY; [‐]NAN or [‐]NAN(string).
Top | Up | Prev | Next | Up and Next
(More later—not yet a priority) ☺
Top | Up | Prev | Next | Up and Next
This section is not about new integer types which have been introduced to the standard—long long int is the only such new type. This section talks about a plethora of new typedefs which come with certain guarantees.
These guarantees come in handy, because up until now it has been hard to assume very much at all about the standard integer types. For instance, we know that short must be at least 16 bits wide, as we have certain guarantees about the minimum range that must be representable by it—but we don’t know if it might be somewhat larger than that. If you are trying to write code that produces a buffer of sound samples for playing on a 16‐bit 44KHz device, you need to know what integer type has a width of exactly 16 bits.
You may also have other things to consider—you may not care if an integer type has more bits than you will be needing, but you might care that arithmetic operations using it be as fast as possible. It might be that a long long might be better suited for your needs, even if your values will never exceed 32,767, because operations with long long might be faster on a particular implementation than with short. But even if you knew what type is best suited for a particular setup, that will probably not be the best solution for all other platforms on which you might wish your code to run. So some typedefs have been provided for types which are at least N bits wide, and as fast as possible for most operations.
Top | Up | Prev | Next | Up and Next
All of the facilities discussed in this subsection are found in the standard header file stdint.h.
Top | Up | Prev | Next | Up and Next
Since the C standard makes no requirements as to the size of a byte, and in particular that the sizes of the integer types are a multiple of 8 bits, it is not possible to guarantee that a type which is, e.g., exactly 16 bits is even available. However, C99 requires that, if integer types are available with widths of 8, 16, 32, or 64 bits, a corresponding typedef of an identifier with the pattern intN_t (where N is the width in bits) be made available in stdint.h, along with uintN_t for the unsigned counterpart. These types are guaranteed to have no padding bits and to be represented using two’s complement—so if these types are defined, you don’t have to do any guessing about their representation. Types in any other width that conform to these guarantees may also be defined.
For each of these types defined, the macros INTN_MIN, INTN_MAX, UINTN_MAX shall also be defined, with the values −(2N−1), 2N−1−1, and 2N−1, respectively.
Top | Up | Prev | Next | Up and Next
typedef names in the pattern int_leastN_t are defined to be the smallest signed integer type that is at least N bits wide. The pattern uint_leastN_t is the unsigned equivalent. Such typedefs are guaranteed to be provided for N equals 8, 16, 32, and 64. All other such types are optional.
For each type so defined, the macros INT_LEASTN_MIN, INT_LEASTN_MAX, and UINT_LEASTN_MAX are also defined, with values of at most −(2N−1−1), at least 2N−1−1, and at least 2N−1, respectively.
Also defined for each such type is a function‐like macro INTN_C(), which takes a single integer constant parameter. It expands to the value of the parameter, expressed in the type int_leastN_t, still as an integer constant. For example, if int_least32_t is a typedef for long int, then the expression INT32_C(293864) might expand to 293864L. UINTN_C() is the unsigned equivalent.
Top | Up | Prev | Next | Up and Next
typedefs of the pattern
int_fastN_t are
intended to be the fastest signed integers that are at least
N bits
wide. uint_fastN_t
is the unsigned counterpart. What makes an integer
the fastest
is somewhat difficult to
determine—a given integer might be faster than others for
some purposes, but slower for others—but using such a type
is at least more likely to help keep things moving along
than using some other type. These types are guaranteed to be
defined for N=8, 16, 32, and 64;
any others are optional.
For each such type defined, the macros INT_FASTN_MIN, INT_FASTN_MAX, and UINT_FASTN_MAX are defined, with the same value requirements as for the int_leastN_t types.
Top | Up | Prev | Next | Up and Next
The types intptr_t and uintptr_t correspond, respectively, to a signed and unsigned integer type to which a value of type pointer‐to‐void may be converted, and the value converted back to pointer‐to‐void will compare equal to the original pointer. These types are optional, and not guaranteed to be provided. If they are, then the macros INTPTR_MIN, INTPTR_MAX, UINTPTR_MAX.
The type intmax_t is the largest signed integer type provided by the implementation (possibly larger than any of the standard types, including long long), and uintmax_t is the largest unsigned type. Macros INTMAX_MIN, INTMAX_MAX, and UINTMAX_MAX, the magnitude of whose values must obviously be at least those of long long and unsigned long long. A function‐like macro, INTMAX_C(), is provided which expands to an integer constant with the value of its parameter, expressed as an intmax_t; also provided is the unsigned counterpart, UINTMAX_C(). For example, if uintmax_t is aliased to unsigned long long int, then UINTMAX_C(802) might expand to 802ULL.
Top | Up | Prev | Next | Up and Next
Besides the macros defined to express the limits for new typedefs introduced by the stdint.h header, there are also macros for discovering the limits of a few other typedef‐defined types—ptrdiff_t, sig_atomic_t, size_t, wchar_t, and wint_t. Each of these macros are defined using the name of the type in uppercase, with the final t replaced by MIN or MAX. size_t doesn’t get a SIZE_MIN, since it is defined to be an unsigned type.
Top | Up | Prev | Next | Up and Next
The inttypes.h header file contains facilities for using the types defined in stdint.h with the formatted input/output functions such as printf() and scanf(); and also several facilities that are handy for performing operations with the intmax_t type. The inttypes.h header also automatically includes the contents of stdint.h.
Top | Up | Prev | Next | Up and Next
inttypes.h provides a macro for each type defined in stdint.h, which will expand to a string literal containing a conversion specifier, optionally preceded by a length modifier, for use with printf() or scanf(). Separate macros are provided for printf() and scanf(), as the specifiers and/or length modifiers may differ for the two function families on a given type.
The printf() macros begin with PRI, and the scanf() macros begin with SCN. This is then followed by the desired specifier (d, i, o, u, x or X), and then a name which is similar to the name of the corresponding type in stdint.h.
The macros defined for the printf() family are:
| PRIwN | PRIwLEASTN | PRIwFASTN | PRIwMAX | PRIwPTR |
where w is replaced by any of the integer specifiers mentioned above. The scanf() versions are named in the same way, except that they begin with SCN instead of PRI.
#include <inttypes.h>
int main(void)
{
uintmax_t u = UINTMAX_MAX;
printf("The largest integer value representable on this\n"
"implementation is %#016" PRIxMAX ", "
"or %" PRIdMAX " decimal.\n");
return 0;
}
Top | Up | Prev | Next | Up and Next
Top | Up | Prev | Next | Up and Next
intmax_t imaxabs(intmax_t j);
imaxabs() computes and returns the absolute value of j. There’s one catch though—if j is equal to INTMAX_MIN, then a two’s complement implementation would be unable to represent its absolute value, as it would be one greater than INTMAX_MAX. Not only will you not get an accurate return value, but the standard decrees this situation to result in undefined behavior—which means that nsaty things could happen. So make sure you only use imaxabs() if j’s absolute value is representable.
Top | Up | Prev | Next | Up and Next
imaxdiv_t imaxdiv(intmax_t numer, intmax_t denom);
This function computes numer / denom and numer % denom, but it is performed as a single operation, if possible. The return value is a structure with two fields: quot, which contains the quotient; and rem, which holds the remainder. Both are intmax_ts. If either the quotient or the remainder cannot be expressed, behavior is again undefined, so be sure to check your inputs (i.e., don’t divide by or into zero, and don’t divide INTMAX_MIN by –1 on two’s complement systems).
Top | Up | Prev | Next | Up and Next
The functions strtoimax(), strtoumax(), wcstoimax(), and wcstoumax are available in inttypes.h, and are equivalent to strtol, strtoul, wcstol, and wcstoul (respectively), except that conversion is done to intmax_t or uintmax_t instead of long or unsigned long.
Top | Up | Prev | Next | Up and Next
C99 has added a couple of convenient features for defining macros.
Top | Up | Prev | Next | Up and Next
In C90 and prior, it has been rather awkward to define macros which wrap functions with a variable number of arguments, since it hasn’t been possible to define macros which are capable of accepting a variable number of arguments.
For instance, you might wish to create a macro which accepts a format string and associated arguments, which will call fprintf() when the program has been compiled to produce debugging information, but which will do nothing when compiled for production. But this is rather awkward. You could write one to be invoked like so:
MYDEBUGF((format‐string, arg1, arg2, …));
since everything within the inner parens would be considered a single argument, but this is undesirable since it doesn’t look like a function call anymore, and sticks out like a sore thumb.
C99 has added the ability to define function‐like macros which can accept a variable number of arguments. These can be defined by placing ... as the final parameter to the macro. They are accessible within the macro’s replacement list by the special identifier __VA_ARGS__, which will be replaced with the trailing parameters to the macro, including the commas.
So, for example, you can now write a more comfortable debug macro which might be defined like:
#define STR(x) #x
#if DEBUG_MODE
# define MYSECRETDEBUGF(format, file, line, ...) \
fprintf(stderr, file ", line " STR(line) ", %s: " \
format "\n", __func__, __VA_ARGS__)
# define MYDEBUGF(format, ...) MYSECRETDEBUGF(format, __FILE__, \
__LINE__, __VA_ARGS__)
#else
# define MYDEBUGF(...) // Do nothing.
#endif
If you invoked the MYDEBUF macro as follows (on, say, line 53 of vamacex.c):
MYDEBUGF("foo's value is %d; bar's is %d.", foo, bar);
it would be expanded to:
fprintf(strerr, "vamacex.c" ", line " "53" ", %s(): "
"foo's value is %d; bar's is %d." "\n", __func__, foo, bar);
(Or, after string literal concatenation:)
fprintf(strerr, "vamacex.c, line 53, %s(): foo's value is %d; "
"bar's is %d.\n", __func__, foo, bar);
Which, if debugging is on, might produce something like the following:
vamacex.c, line 53, testfubar(): foo's value is 19, bar's is -4395.
Top | Up | Prev | Next | Up and Next
In C90, the behavior was undefined if a macro was given an empty argument; e.g., if a macro was defined like:
#define MYMACRO(a, b, c) #a " loves " #b "..." #c
You could obtain "Harry loves Sally...deeply" with MYMACRO(Harry, Sally, deeply); but you could not obtain "Harry loves Sally..." with MYMACRO(Harry, Sally,), as that produces undefined behavior.
However, in C99, empty macro arguments have been legalized, so the latter invocation is quite alright, and will produce the expected results.
Top | Up | Prev | Next | Up and Next
It is somewhat common practice among those who are somewhat less‐than‐strict about writing well‐formed code to create structures and use structures such as:
#include <stdlib.h>
struct foo
{
int field1;
double field2;
size_t bufsize;
char buffer[0];
};
int main(void)
{
struct foo *fooptr;
size_t foobufsz = 256;
char *fret;
int sret;
fooptr = malloc( (sizeof *fooptr) + foobufsz );
// Handle fooptr == NULL.
fooptr->bufsize = foobufsz;
fret = fgets(fooptr->buffer, fooptr->bufsize, stdin);
// Handle fret == NULL.
sret = sscanf("%d,%lf", &fooptr->field1, &fooptr->field2);
…
return 0;
}
At , a struct is
defined with a final member, buffer,
whose type is a zero‐length array. Then, at , freshly allocated space is assigned to
pointer to the new struct type, with not only
enough space to hold an object of type struct foo,
but plenty more besides. At ,
the struct foo’s buffer
field is accessed
, even though it has been
defined to have zero elements—and therefore, zero size. But,
since valid, addressable space exists at the locations which
would be elements of buffer if it had
been defined to be a size encompassing the extra allocated
space, the programmers who write code in this style apparently
feel safe in doing so.
However, as far as the standard is concerned, the behavior of such code is undefined; from the very moment that buffer is converted to a pointer, it is not allowed to be used with additive operators to produce a value which points anywhere outside the array or one element past it—which, in this case, means anywhere other than where it points now. And, since by definition, such a pointer already points one past the array’s last element, it is not allowed to be dereferenced, either.
Dennis Ritchie, the inventor of the C language, calls this style of programming “getting chummy with the implementation.” No implementation is known to exist which will behave in any way other than is generally expected—but that does mean that such an implementation cannot exist. For instance, an implementation might exist that performs dynamic bounds‐checking on all pointer accesses—such an implementation would be perfectly within its rights to halt execution (or, for that matter, cause dæmons to fly out of your nose, as far as the standard is concerned).
But the C99 standard has sanctioned a method for achieving the same affect: it is permitted to define, as the final member of a struct, an array with incomplete type (e.g., int final_mem[];), called a flexible array member. This member is ignored for most purposes, but it may be legally used to access space beyond the defined size of the struct, when that struct is part of or immediately adjacent to an object which encompasses that space. So, the code above would be legal in C99, provided the definition were changed to:
struct foo
{
int field1;
double field2;
size_t bufsize;
char buffer[];
};
Top | Up | Prev | Next | Up and Next
C99 has defined a new type qualifier, restrict. This qualifier may only be applied to pointer types.
Declaring a pointer to be restrict‐qualified constitutes a promise that no object which is accessed through that pointer will be accessed by any means except through that pointer, within the block associated with the declaration of the restricted type (if the declaration is file‐scope, then that block is main()’s), unless the object so‐accessed is never modified during that block’s execution. Violations of this guarantee produce undefined behavior. This gives C implementations to employ better code optimizations than would otherwise be possible.
For example, for a function defined:
void copyints(size_t s, int * restrict a, int *b)
{
while (s--)
*a++ = *b++;
}
the compiler may generate code based on the assumption that if an object is accessed via a, it will not also be accessed via b (i.e., if a and b are both arrays of s ints, they do not overlap). Note that only one of a and b need be restrict‐qualified in order to represent this guarantee.
But, for a function defined:
void add_arrays(size_t s, int * restrict result, int * restrict a,
int * restrict b)
{
size_t i;
for (i=s; i != s; ++i)
result[i] = a[i] + b[i];
}
It would be perfectly alright for arrays into by a and b to overlap—over even for the two pointers to have the same value—provided that they are still distinct from the array pointed at by result, since the objects pointed at by a and b are not modified within this block.
Another restriction placed on restrict‐qualified pointers is that the value of an expression based on such a pointer may not be assigned to another restrict‐qualified pointer, unless either the pointer used in the expression has a scope which begins before that of the pointer to which the assignment is being made, or the pointer used in the expression is from the result of a function. For example:
{
int restrict * p1;
{
int restrict * p2;
int restrict * p3;
p2 = p1;
p1 = p3; // No!
}
}
In the above block of code, the assignment at is legal, since
p1’s scope begins before
p2’s; but the assignment at is not, for the same
reason.
Many function prototypes that have existed in the C
standard library have been reworked in C99, using the restrict qualifier to protect pointer
parameters; these generally won’t change the behavior of
well‐defined C90 code, since while these requirements weren’t
made explicitly in the prototypes themselves, they were still
decreed within the text of the C standard. See Appendix A,
for a list of the functions that
have been changed in this way.Restricted
Functions
Top | Up | Prev | Next | Up and Next
It is now allowed for arrays which are declared as function parameters to contain type specifiers within the [ and ] of the array declarator furthest to the left in the declaration. If an expression is included in the declarator, it occurs after the type specifiers. Such an array type is adjusted to a pointer (as always with array parameters), which is qualified by the qualifiers in the array declarator. So, for instance, the declaration:
void myfun(const int a[const restrict 10]);
is precisely equivalent to:
void myfun(const int * const restrict);
Thus, the array declaration form is now just as powerful as a pointer declaration for declaring pointer‐type parameters.
Along with type qualifiers, the keyword static may also appear in the declarator (if type qualifiers are also present, they will appear after static), in which case, the array‐size expression is compulsory. In this context, the static keyword indicates a requirement that the pointer passed for that parameter points at the first element of an array which holds at least as many elements as indicated by the array‐size expression. That is, for a function declared:
void otherfun(int a[static 99]);
if the function is called as otherfun(ary), then ary must point into an array of at least 99 ints, or the behavior is undefined.
Top | Up | Prev | Next | Up and Next
C99 now allows you to specify characters from the ISO/IEC 10646 character set in identifiers, and character and string literals. This character set is identical to the Unicode character set, which is a specification of the Unicode Consortium. Not all characters are available for use in identifiers—just the ones that make sense. Punctuation and symbols, etc. are excluded.
Characters from the ISO/IEC 10646 are specified by \u or \U followed by either four or eight hexadecimal digits, representing the character’s short identifier (or Unicode value). Characters with Unicode values less than 00A0 must not be specified using this notation, except for 0024, 0040 or 0060, which represent the dollar sign ($), the at sign (@), and the backtick (`). Those characters are not required to exist in the basic source set, so an alternative method for specifying them may be needed. Also, characters in the range D800 through DFFF must not be specified (these codepoints are used for surrogates in the 16‐bit Unicode encoding UTF–16, to combine with other surrogates to specify characters with values in the range 10000 through 1FFFFF.
Usually, you will not be specifying universal character names directly. The main idea is that the C preprocessor automatically convert characters from the character sets it support into universal character names, as necessary. Actually, it’s not really even necessary that the preprocessor do that much—so long as your C implementation behaves as if it did. Or, you could use a source code editor which displays international characters, but saves and loads using universal character names. However it is done, chances are good that you can enter international characters using a more familiar input system, and they will end up being processed as universal character names somewhere down the line. However, if you’re using a C99 implementation which doesn’t support a character set which includes a character you’re interested in, you can always specify it directly using the universal character name notation.
Below are examples of identifiers which use universal character names:
FILE *résumé = fopen("my_resume.txt", "r");
Node *αλφα = NULL, *ωμηγα = NULL;
const char *ストリング = "今日は、世界";
which are equivalent to:
FILE *r\U00e9sum\U00e9 = fopen("my_resume.txt", "r");
Node *\u03B1\u03BB\u03C6\u03B1 = NULL, *\u03C9\u03BC\u03B7\u03B3\u03B1 = NULL;
const char *\u30b9\u30c8\u30ea\u30f3\u30b0 = "\u4eca\u65e5\u306f\u3001\u4e16\u754c";
Top | Up | Prev | Next | Up and Next
Support for complex and imaginary number arithmetic has been added to C99. The three new complex types are: float _Complex, double _Complex, and long double _Complex; the imaginary types are float _Imaginary, double _Imaginary, and long double _Imaginary. No implementation is required to support the imaginary types, and freestanding implementations (e.g., those used in most embedded systems) are not required to support the complex types. The imaginary types, if present, are represented identically to their real counterparts; and the complex types are represented idfrom the rentically to an array of two elements of the corresponding real floating‐point type, where the first element represents the real part, and the second element represents the imaginary part.
The complex.h standard library header contains the macro definitions complex and imaginary, which expand to _Complex and _Imaginary, respectively (if imaginary types aren’t supported, than the latter macro is not defined). So #includeing that header allows you to refer to the types as, e.g., double complex or long double imaginary.
Also defined are the macros _Complex_I and _Imaginary_I, which expand to a constant expression, of types float _Complex and float _Imaginary, respectively, with the value of the imaginary unit (or, the square root of −1). _Imaginary_I is not defined if imaginary numbers are not supported. Another macro, I, is defined to expand to either _Complex_I or _Imaginary_I.
Note that if an implementation doesn’t support the imaginary types, it is still perfectly possible to specify every imaginary number using a complex type. Complex numbers can be specified in the form (e.g.) 3 + 5 * I, which would have a real part of 3.0, and an imaginary part of 5.0.
complex.h also includes a complex version of virtually every floating‐point trigonometric, hyperbolic, exponential, power and absolute‐value function declared in math.h. Each of these has the same name as the equivalent function found in math.h, except that the letter c has been prepended to it. For example, the function for determining the cosine of a double _Complex is declared:
double complex ccos(double complex z);
Other facilities are also provided in complex.h. Other notable functions include:
double creal(double complex z); float crealf(float complex z); long double creall(long double complex z);
which return the real portion of the complex argument, and:
double cimag(double complex z); float cimagf(float complex z); long double cimagl(long double complex z);
which return the imaginary portion of the complex argument (as a real number).
Top | Up | Prev | Next | Up and Next
…
Top | Up | Prev | Next | Up and Next
Copyright (C) 2000,2001,2002 Free Software Foundation, Inc. 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA Everyone is permitted to copy and distribute verbatim copies of this license document, but changing it is not allowed.
Top | Up | Prev | Next | Up and Next
The purpose of this License is to make a manual, textbook, or other functional and useful document "free" in the sense of freedom: to assure everyone the effective freedom to copy and redistribute it, with or without modifying it, either commercially or noncommercially. Secondarily, this License preserves for the author and publisher a way to get credit for their work, while not being considered responsible for modifications made by others.
This License is a kind of "copyleft", which means that derivative works of the document must themselves be free in the same sense. It complements the GNU General Public License, which is a copyleft license designed for free software.
We have designed this License in order to use it for manuals for free software, because free software needs free documentation: a free program should come with manuals providing the same freedoms that the software does. But this License is not limited to software manuals; it can be used for any textual work, regardless of subject matter or whether it is published as a printed book. We recommend this License principally for works whose purpose is instruction or reference.
Top | Up | Prev | Next | Up and Next
This License applies to any manual or other work, in any medium, that contains a notice placed by the copyright holder saying it can be distributed under the terms of this License. Such a notice grants a world-wide, royalty-free license, unlimited in duration, to use that work under the conditions stated herein. The "Document", below, refers to any such manual or work. Any member of the public is a licensee, and is addressed as "you". You accept the license if you copy, modify or distribute the work in a way requiring permission under copyright law.
A "Modified Version" of the Document means any work containing the Document or a portion of it, either copied verbatim, or with modifications and/or translated into another language.
A "Secondary Section" is a named appendix or a front-matter section of the Document that deals exclusively with the relationship of the publishers or authors of the Document to the Document's overall subject (or to related matters) and contains nothing that could fall directly within that overall subject. (Thus, if the Document is in part a textbook of mathematics, a Secondary Section may not explain any mathematics.) The relationship could be a matter of historical connection with the subject or with related matters, or of legal, commercial, philosophical, ethical or political position regarding them.
The "Invariant Sections" are certain Secondary Sections whose titles are designated, as being those of Invariant Sections, in the notice that says that the Document is released under this License. If a section does not fit the above definition of Secondary then it is not allowed to be designated as Invariant. The Document may contain zero Invariant Sections. If the Document does not identify any Invariant Sections then there are none.
The "Cover Texts" are certain short passages of text that are listed, as Front-Cover Texts or Back-Cover Texts, in the notice that says that the Document is released under this License. A Front-Cover Text may be at most 5 words, and a Back-Cover Text may be at most 25 words.
A "Transparent" copy of the Document means a machine-readable copy, represented in a format whose specification is available to the general public, that is suitable for revising the document straightforwardly with generic text editors or (for images composed of pixels) generic paint programs or (for drawings) some widely available drawing editor, and that is suitable for input to text formatters or for automatic translation to a variety of formats suitable for input to text formatters. A copy made in an otherwise Transparent file format whose markup, or absence of markup, has been arranged to thwart or discourage subsequent modification by readers is not Transparent. An image format is not Transparent if used for any substantial amount of text. A copy that is not "Transparent" is called "Opaque".
Examples of suitable formats for Transparent copies include plain ASCII without markup, Texinfo input format, LaTeX input format, SGML or XML using a publicly available DTD, and standard-conforming simple HTML, PostScript or PDF designed for human modification. Examples of transparent image formats include PNG, XCF and JPG. Opaque formats include proprietary formats that can be read and edited only by proprietary word processors, SGML or XML for which the DTD and/or processing tools are not generally available, and the machine-generated HTML, PostScript or PDF produced by some word processors for output purposes only.
The "Title Page" means, for a printed book, the title page itself, plus such following pages as are needed to hold, legibly, the material this License requires to appear in the title page. For works in formats which do not have any title page as such, "Title Page" means the text near the most prominent appearance of the work's title, preceding the beginning of the body of the text.
A section "Entitled XYZ" means a named subunit of the Document whose title either is precisely XYZ or contains XYZ in parentheses following text that translates XYZ in another language. (Here XYZ stands for a specific section name mentioned below, such as "Acknowledgements", "Dedications", "Endorsements", or "History".) To "Preserve the Title" of such a section when you modify the Document means that it remains a section "Entitled XYZ" according to this definition.
The Document may include Warranty Disclaimers next to the notice which states that this License applies to the Document. These Warranty Disclaimers are considered to be included by reference in this License, but only as regards disclaiming warranties: any other implication that these Warranty Disclaimers may have is void and has no effect on the meaning of this License.
Top | Up | Prev | Next | Up and Next
You may copy and distribute the Document in any medium, either commercially or noncommercially, provided that this License, the copyright notices, and the license notice saying this License applies to the Document are reproduced in all copies, and that you add no other conditions whatsoever to those of this License. You may not use technical measures to obstruct or control the reading or further copying of the copies you make or distribute. However, you may accept compensation in exchange for copies. If you distribute a large enough number of copies you must also follow the conditions in section 3.
You may also lend copies, under the same conditions stated above, and you may publicly display copies.
Top | Up | Prev | Next | Up and Next
If you publish printed copies (or copies in media that commonly have printed covers) of the Document, numbering more than 100, and the Document's license notice requires Cover Texts, you must enclose the copies in covers that carry, clearly and legibly, all these Cover Texts: Front-Cover Texts on the front cover, and Back-Cover Texts on the back cover. Both covers must also clearly and legibly identify you as the publisher of these copies. The front cover must present the full title with all words of the title equally prominent and visible. You may add other material on the covers in addition. Copying with changes limited to the covers, as long as they preserve the title of the Document and satisfy these conditions, can be treated as verbatim copying in other respects.
If the required texts for either cover are too voluminous to fit legibly, you should put the first ones listed (as many as fit reasonably) on the actual cover, and continue the rest onto adjacent pages.
If you publish or distribute Opaque copies of the Document numbering more than 100, you must either include a machine-readable Transparent copy along with each Opaque copy, or state in or with each Opaque copy a computer-network location from which the general network-using public has access to download using public-standard network protocols a complete Transparent copy of the Document, free of added material. If you use the latter option, you must take reasonably prudent steps, when you begin distribution of Opaque copies in quantity, to ensure that this Transparent copy will remain thus accessible at the stated location until at least one year after the last time you distribute an Opaque copy (directly or through your agents or retailers) of that edition to the public.
It is requested, but not required, that you contact the authors of the Document well before redistributing any large number of copies, to give them a chance to provide you with an updated version of the Document.
Top | Up | Prev | Next | Up and Next
You may copy and distribute a Modified Version of the Document under the conditions of sections 2 and 3 above, provided that you release the Modified Version under precisely this License, with the Modified Version filling the role of the Document, thus licensing distribution and modification of the Modified Version to whoever possesses a copy of it. In addition, you must do these things in the Modified Version:
Use in the Title Page (and on the covers, if any) a title distinct from that of the Document, and from those of previous versions (which should, if there were any, be listed in the History section of the Document). You may use the same title as a previous version if the original publisher of that version gives permission.
List on the Title Page, as authors, one or more persons or entities responsible for authorship of the modifications in the Modified Version, together with at least five of the principal authors of the Document (all of its principal authors, if it has fewer than five), unless they release you from this requirement.
State on the Title page the name of the publisher of the Modified Version, as the publisher.
Preserve all the copyright notices of the Document.
Add an appropriate copyright notice for your modifications adjacent to the other copyright notices.
Include, immediately after the copyright notices, a license notice giving the public permission to use the Modified Version under the terms of this License, in the form shown in the Addendum below.
Preserve in that license notice the full lists of Invariant Sections and required Cover Texts given in the Document's license notice.
Include an unaltered copy of this License.
Preserve the section Entitled "History", Preserve its Title, and add to it an item stating at least the title, year, new authors, and publisher of the Modified Version as given on the Title Page. If there is no section Entitled "History" in the Document, create one stating the title, year, authors, and publisher of the Document as given on its Title Page, then add an item describing the Modified Version as stated in the previous sentence.
Preserve the network location, if any, given in the Document for public access to a Transparent copy of the Document, and likewise the network locations given in the Document for previous versions it was based on. These may be placed in the "History" section. You may omit a network location for a work that was published at least four years before the Document itself, or if the original publisher of the version it refers to gives permission.
For any section Entitled "Acknowledgements" or "Dedications", Preserve the Title of the section, and preserve in the section all the substance and tone of each of the contributor acknowledgements and/or dedications given therein.
Preserve all the Invariant Sections of the Document, unaltered in their text and in their titles. Section numbers or the equivalent are not considered part of the section titles.
Delete any section Entitled "Endorsements". Such a section may not be included in the Modified Version.
Do not retitle any existing section to be Entitled "Endorsements" or to conflict in title with any Invariant Section.
Preserve any Warranty Disclaimers.
If the Modified Version includes new front-matter sections or appendices that qualify as Secondary Sections and contain no material copied from the Document, you may at your option designate some or all of these sections as invariant. To do this, add their titles to the list of Invariant Sections in the Modified Version's license notice. These titles must be distinct from any other section titles.
You may add a section Entitled "Endorsements", provided it contains nothing but endorsements of your Modified Version by various parties--for example, statements of peer review or that the text has been approved by an organization as the authoritative definition of a standard.
You may add a passage of up to five words as a Front-Cover Text, and a passage of up to 25 words as a Back-Cover Text, to the end of the list of Cover Texts in the Modified Version. Only one passage of Front-Cover Text and one of Back-Cover Text may be added by (or through arrangements made by) any one entity. If the Document already includes a cover text for the same cover, previously added by you or by arrangement made by the same entity you are acting on behalf of, you may not add another; but you may replace the old one, on explicit permission from the previous publisher that added the old one.
The author(s) and publisher(s) of the Document do not by this License give permission to use their names for publicity for or to assert or imply endorsement of any Modified Version.
Top | Up | Prev | Next | Up and Next
You may combine the Document with other documents released under this License, under the terms defined in section 4 above for modified versions, provided that you include in the combination all of the Invariant Sections of all of the original documents, unmodified, and list them all as Invariant Sections of your combined work in its license notice, and that you preserve all their Warranty Disclaimers.
The combined work need only contain one copy of this License, and multiple identical Invariant Sections may be replaced with a single copy. If there are multiple Invariant Sections with the same name but different contents, make the title of each such section unique by adding at the end of it, in parentheses, the name of the original author or publisher of that section if known, or else a unique number. Make the same adjustment to the section titles in the list of Invariant Sections in the license notice of the combined work.
In the combination, you must combine any sections Entitled "History" in the various original documents, forming one section Entitled "History"; likewise combine any sections Entitled "Acknowledgements", and any sections Entitled "Dedications". You must delete all sections Entitled "Endorsements".
Top | Up | Prev | Next | Up and Next
You may make a collection consisting of the Document and other documents released under this License, and replace the individual copies of this License in the various documents with a single copy that is included in the collection, provided that you follow the rules of this License for verbatim copying of each of the documents in all other respects.
You may extract a single document from such a collection, and distribute it individually under this License, provided you insert a copy of this License into the extracted document, and follow this License in all other respects regarding verbatim copying of that document.
Top | Up | Prev | Next | Up and Next
A compilation of the Document or its derivatives with other separate and independent documents or works, in or on a volume of a storage or distribution medium, is called an "aggregate" if the copyright resulting from the compilation is not used to limit the legal rights of the compilation's users beyond what the individual works permit. When the Document is included an aggregate, this License does not apply to the other works in the aggregate which are not themselves derivative works of the Document.
If the Cover Text requirement of section 3 is applicable to these copies of the Document, then if the Document is less than one half of the entire aggregate, the Document's Cover Texts may be placed on covers that bracket the Document within the aggregate, or the electronic equivalent of covers if the Document is in electronic form. Otherwise they must appear on printed covers that bracket the whole aggregate.
Top | Up | Prev | Next | Up and Next
Translation is considered a kind of modification, so you may distribute translations of the Document under the terms of section 4. Replacing Invariant Sections with translations requires special permission from their copyright holders, but you may include translations of some or all Invariant Sections in addition to the original versions of these Invariant Sections. You may include a translation of this License, and all the license notices in the Document, and any Warrany Disclaimers, provided that you also include the original English version of this License and the original versions of those notices and disclaimers. In case of a disagreement between the translation and the original version of this License or a notice or disclaimer, the original version will prevail.
If a section in the Document is Entitled "Acknowledgements", "Dedications", or "History", the requirement (section 4) to Preserve its Title (section 1) will typically require changing the actual title.
Top | Up | Prev | Next | Up and Next
You may not copy, modify, sublicense, or distribute the Document except as expressly provided for under this License. Any other attempt to copy, modify, sublicense or distribute the Document is void, and will automatically terminate your rights under this License. However, parties who have received copies, or rights, from you under this License will not have their licenses terminated so long as such parties remain in full compliance.
Top | Up | Prev | Next | Up and Next
The Free Software Foundation may publish new, revised versions of the GNU Free Documentation License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns. See http://www.gnu.org/copyleft/.
Each version of the License is given a distinguishing version number. If the Document specifies that a particular numbered version of this License "or any later version" applies to it, you have the option of following the terms and conditions either of that specified version or of any later version that has been published (not as a draft) by the Free Software Foundation. If the Document does not specify a version number of this License, you may choose any version ever published (not as a draft) by the Free Software Foundation.
Top | Up | Prev | Next | Up and Next
To use this License in a document you have written, include a copy of the License in the document and put the following copyright and license notices just after the title page:
Copyright (c) YEAR YOUR NAME. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled "GNU Free Documentation License".
If you have Invariant Sections, Front-Cover Texts and Back-Cover Texts, replace the "with...Texts." line with this:
with the Invariant Sections being LIST THEIR TITLES, with the Front-Cover Texts being LIST, and with the Back-Cover Texts being LIST.
If you have Invariant Sections without Cover Texts, or some other combination of the three, merge those two alternatives to suit the situation.
If your document contains nontrivial examples of program code, we recommend releasing these examples in parallel under your choice of free software license, such as the GNU General Public License, to permit their use in free software.